Decentralized discovery
Often the first thing brought up when discussing decentralized content is the difficulty of discovery. Big Tech has all these data points combining the content on their platform with all the consumers so they can make educated guesses to route people to content that benefit the platform, data brokers, advertisers, governments, and lastly somewhere down the line the consumers. How can those who want to opt out of those networks compete in this game? I argue that we don’t. We play a different game.
Below are some broad topics I want to discuss around discovery. It’s not about any specific project or technology, it’s just my thoughts. However, before I go further I want to make something unequivocally clear. I want everyone to internalize this deep within their soul.
It’s the default. We literally have to do nothing to have a decentralized internet. Every service a person brings online is a new entry in this beautiful network that is connected by standards and available without gatekeepers. Every new web site adds to the grand tapestry that is the World Wide Web, sharing knowledge, content and experiences. Every new XMPP server allows a community to communicate with each other, and to the greater internet. Every new Fediverse node grows an interconnected social network with different views, rules, communities and content.
On the flip side, it takes an unbelievable amount of money, personnel and power to build a locked-in empire. Yet here we are, surrounded by locked-in empires.
We’ve resorted to thinking discovery is an algorithm telling us what to consume, or a protocol feeding us the next something. But do you like this way of consuming? Is it even accurate? Do you want more machines feeding you content, or are we just used to it?
To give my opinions some credence let’s quickly refer to a creator who uses a Big Tech platform for his livelihood. The Nostalgia Nerd is a YouTuber with about half a million subscribers. He recently shared how his content isn’t getting to the people who care about it, and voiced his frustrations about content from smaller content creators not being able to reach those who would enjoy it.
So he made some requests:
- Don’t rely on the algorithm. Proactively visit content you want to watch and follow them elsewhere to keep up to date.
- Go visit the 10 creators that he recommends.
And there lies the specifics of decentralized discovery.
Topics I want to discuss Link to heading
Curation Link to heading
What’s a proven way to discover content in a decentralized way? Have people tell you about it.
In the above example, purely out of frustration, The Nostalgia Nerd briefly pivoted from being a content creator who relied on the algorithm to a curator working around the algorithm.
We’re natural curators. You tell your friends your favorite song, your favorite movie, your favorite writers. For others it’s far more formal. You have a newsletter with suggested links and topics, or a playlist with your favorite songs. Some people even make a living curating topics, news, recommendations or entertainment. This has been around forever, and as much as we pretend we’ve given ourselves up to the machine, human-powered curation is bigger than ever.
Curation Examples Link to heading
Letterboxd
I personally use Letterboxd to discover movies and read reviews from everyday people. I don’t use an algorithm there, I instead browse through the “Best 50 dystopian sci-fi” list and pick one I haven’t seen yet.
Twitch Raids
On Twitch you can “Raid” another live stream by sending all your viewers over to them. The streamer picks one live stream that they want their viewers to experience.
Content Journalism
Blogs, newsletters, videos. For example, I always look forward to Marc Ruxin’s end of year movie list to see what films he’s suggested because I’ve always found his recommendations to be spot on with my tastes.
Old Skewl Stuff
Remember Blogrolls? Webrings? Or pages on your site that listed “Friends”? I’m not saying we need to go back to those days, but those things, though they seem quaint now, served a real purpose. Maybe we can learn something from the past.
Social Media Accounts
FediVideo curates video content on the Fediverse that people should check out. They do a fantastic job in helping people discover new content from across the Fediverse on different sites, servers and platforms.
Playlisting
While I’m not going to tell you Spotify is a bastion of openness, it does lead to a modern example of curation. Spotify playlisting has become an industry. And while I wish they weren’t so “pay to play”, that’s kind of the beauty of it. There’s a place for commercial playlisting in the music industry, that’s nothing new. But right next to that commercial playlist is another one run by some indie music fan who wants to share their current favorites. This means you have options. You can look at both. You can compare and contrast.
Bonuses of Curation Link to heading
- Different curators means different opinions. If you don’t think your viewpoint is represented, or an algorithm is biased, then you can take part in people’s discovery process using your thoughts and feelings instead.
- The content doesn’t have to be limited by technology. Build a site highlighting awesome photographers. Some are on Pixelfed, some use 500px, some on Facebook. Compare that to Instagram where they can only recommend Instagram accounts.
- You can start super small without any new tech required. Create a wordpress blog, open a Fediverse account, or just start emailing your friends.
So no algorithms or automated discovery then? Link to heading
While a part of me wants to go all Dune and ban the thinking machines, we all benefit from algorithms. However, as it stands there’s only one user-facing recommendation algorithm per Big Tech platform and it’s built, owned and operated by the same people who have different motives than the consumers and creators of the content. So it’s not that we shouldn’t trust all algorithms, but it’s true that we can’t trust those algorithms.
So maybe there’s a place for us to build our own?
Algorithms require lots of (accurate) data Link to heading
Having different types of algorithms built by different people has been a dream for a long time, but it’s been impossible with our data being locked up in the halls of Big Tech services. The good news is if we decentralize our services, then we have the option to open up our data.
However, even if we did open up all of our respective data, it gets difficult. Say we wanted to replicate the YouTube-style recommendation algorithm but using open data across multiple services. At the very least you’d be wanting to use view count to determine how “popular” a video is so you can recommend it to others. But with the nature of open data, how could you trust that count? Why wouldn’t somebody want to fake their view count in order to get bumped up in the algorithm?
If we’re talking decentralized and open, then you can’t trust it, and there’s no way around that. No signing, no encryption, no authentication can build trust for completely open data when people benefit from faking it.
And while this has always been true, sometimes it doesn’t matter so much. Anybody could build a Fediverse node that lies about the number of followers they have. Sure, that’d be lame, but it wouldn’t really hurt anybody. However, if you use that number for active decision making, such as suggesting accounts to follow, then it would be a big problem.
But some algorithms could work Link to heading
Take for example a decentralized discovery platform you use every day: The search engine. You put in some key words, and some algorithm, powered by completely open data, gives you suggestions that you can click on and navigate to.
Clearly the biggest search engines are not positive examples when it comes to the exact implementations. But high level, this is how it’s supposed to work. And it could work for us too, with enough data and demand.
Interfaces Link to heading
Different types of content benefit from different interfaces. I’ve always been a fan of leveraging standards to allow people to opt into the interface that works best for them. Podcasts, for example, can be consumed with any Podcasting application because of RSS. You can pick and choose what feature set, platform and price works best for you. You also can change interfaces and applications over time, or use different ones in different scenarios.
Using video as an example, let’s check out a couple ways content have been surfaced for discovery.
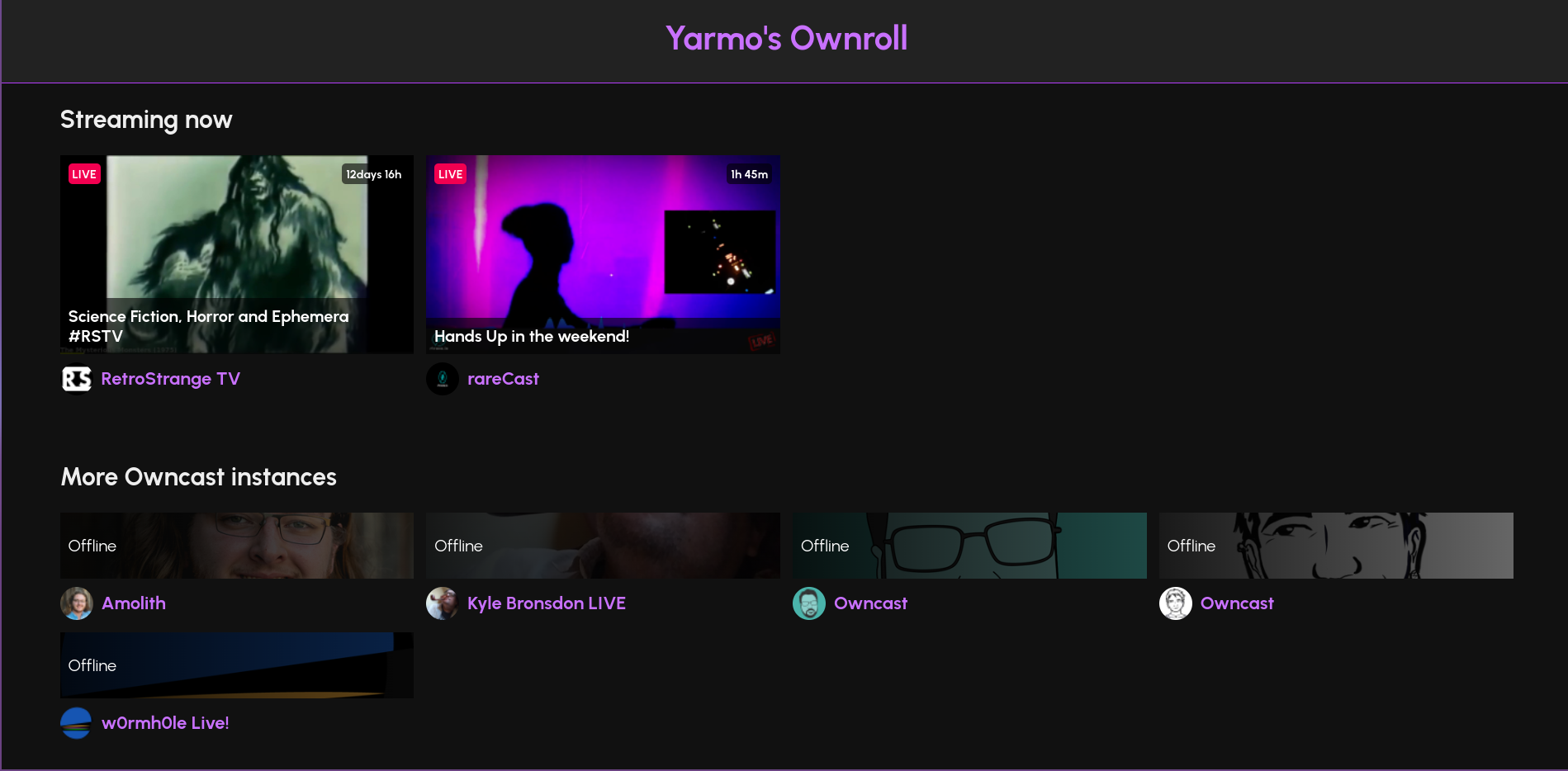
Yarmo built his own interface for surfacing Owncast streams he likes and called it Ownroll. This interface makes a lot of sense when talking about video streams.
PeerTube has a search engine called Sepia for discovering videos.
Owncast has a directory for streamers who choose to be public.
Personally one way I enjoy discovering Owncast streams is I open an application on my AppleTV and it shows me a bunch of streams that are currently live. I navigate to one, and select it, and I watch the stream. This is because the Owncast directory offers up a standards-compliant way to access this data.
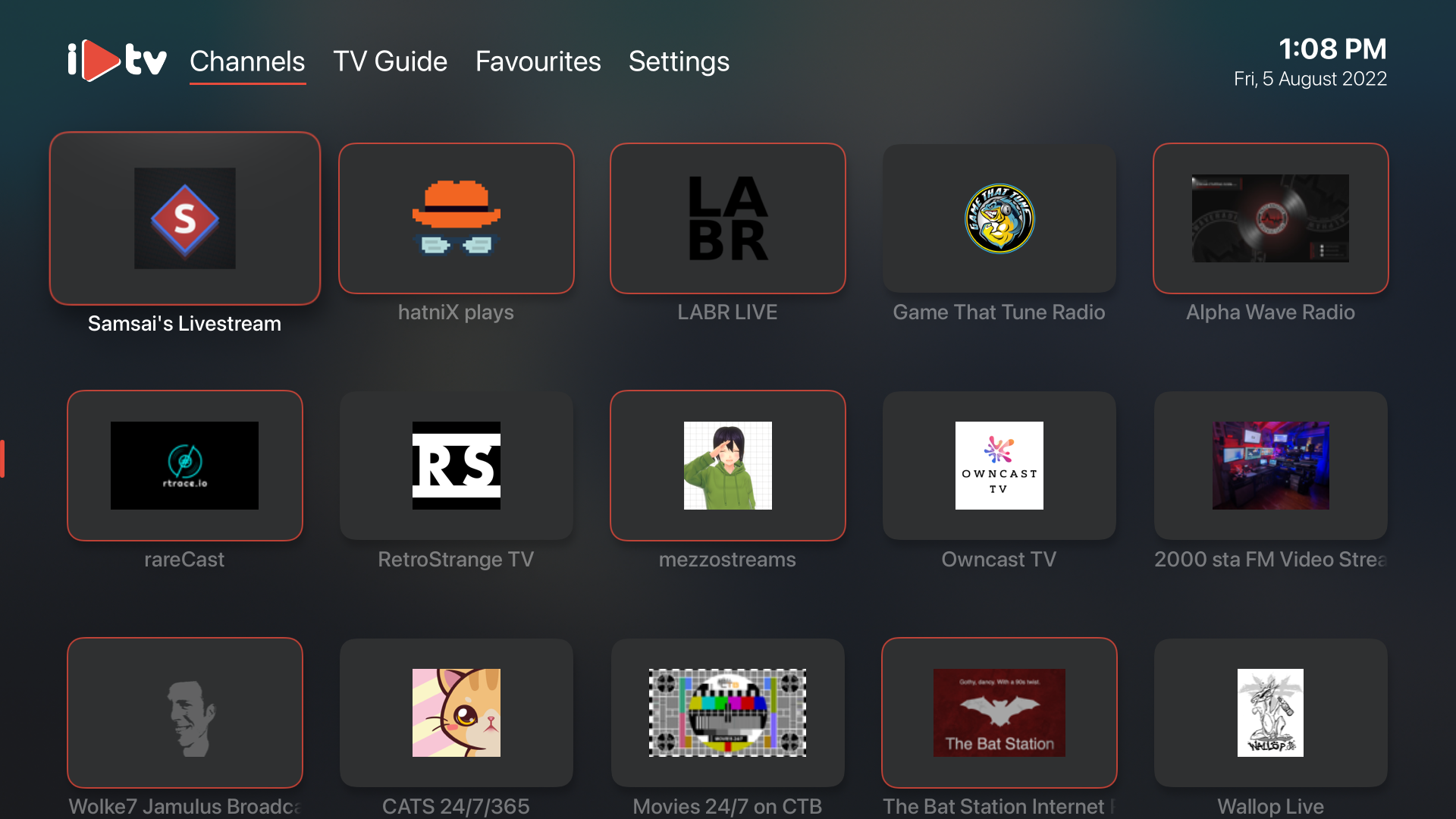
It’s very casual and I can lean back and look at my TV and “see what’s on”, just like people say about cable TV. This doesn’t feel like decentralized content discovery and consumption. It just feels like content. Just like going into the YouTube app, or the Netflix app.
I’ve failed at building decentralized discovery in the past Link to heading
A handful of years ago I built an Internet Radio discovery platform called Longtail Music. It failed.
Internet radio is a fantastic example of a decentralized service. While there are some networks of stations, in general most stations are owned and operated by an individual who is doing it for the love of it. It’s also based on a standard protocol, so people can consume the audio in so many different ways. It’s really great.
I built something that would index all the music that these stations were playing, and then utilize potential listeners’ music tastes either manually, or through streaming services, to determine stations they might like. Pretty straightforward, and I felt like everyone wins. The station owners get new listeners, and the listeners get introduced to a new, free, and very human way to consume music.
I reached out to stations that I thought were doing a great job and said I was building a modern place to highlight quality internet radio and asked if they wanted to be featured. Most said “no”. The reasons were mostly that they incorrectly thought I was trying to sell them something, and I was unable to convince them otherwise. Others thought I was a scammer trying to “steal” their content, or they thought linking to their content from other pages would “steal their listeners”. Mostly it was a general mindset that these people have been independently creating internet radio content for over a decade and assumed I was trying to screw them over somehow because nobody does anything for free.
This mindset was extremely common from people who owned internet radio stations. The independence was fierce. I eventually found this to be an unwinnable battle. If you’re trying to do something for somebody, in this case trying to find listeners for an internet radio station, but they don’t want you involved, then ultimately I built something that just wasn’t wanted and gave up.
Compare this to video streaming Link to heading
Internet Radio, admittedly, is from a different era. And I say this in a positive way. It’s decentralized, independent, free, open, and wonderful.
Compare this to live video streaming, for example. Here the default isn’t free, open, independent, decentralized or wonderful. It’s Twitch and YouTube and Big Tech and walled gardens. And the name of the game for all of these platforms is to get as many viewers as possible by any means possible. Some people who have opted to use something like Owncast to stream independently certainly don’t seem to have that overly aggressive mindset with regards to viewers, but I think most streamers would agree that it would be nice to have viewers and would love you to share their stream to your friends, or your site, or whatever.
So it’s different. I’m not going to use my experience with Longtail Music to say “creators don’t want to be shared with others”, because I don’t believe that to be true.
Final Thoughts Link to heading
I think we’re spoiled by algorithms, but it will be hard to trust completely open data in order to build our own. I personally believe we could use a human touch, but we don’t have enough people wanting to be curators to fill in the gaps. Maybe the tides will change and we’ll stop relying on centralized discovery so much and there will be a variety of options from different people.
I did a lot of writing and I didn’t give a single, specific solution, and for that I apologize. If you were hoping for a protocol, a piece of tech, or a single standard that we can build upon you’re pretty disappointed. So to make up for that I’ll throw you my pie in the sky idea that I’d think about building if I wasn’t working on Owncast. Keep in mind this is just high level brainstorming.
- New ActivityPub powered project that accepts activities from all the decentralized services that speak ActivityPub.
- Unlike projects that are equally about creation and consumption, this would be consumption-only.
- It would follow ActivityPub actors from any service and accept activities from them.
- Things like: stream went live, video was published, blog post was posted, song was uploaded, event was scheduled, etc.
- Admins can create curated lists and sections and override the inevitable faked data.
- I imagine it kind of like a mixture between search results, old-school Yahoo (when it was a directory), and Tumblr, but without a timeline. Just a directory of stuff broken down by types and metadata.
- Just enough rendering of content to know what the content is and assist in discovery.
- Unlike software that do what they can to keep you within your “home server”, this would encourage you to go to the source of the content so you can discover more of it. People deserve the “click” to their actual server, not just embeds.
- It’s not meant to be the place you go to consume all the content you follow. So no home timelines, no algorithmic filtering.
- This project would have no direct affiliation with other projects as to have equal focus handling content from all types of services and encourage standards, no preferential treatment. Content server agnostic.
So there you go, an idea. Take it and run with it and I’ll make sure Owncast sends you all the data you need via ActivityPub.
But clearly we need more people involved for any of this to matter. It can’t be “Owncast builds an Owncast directory, PeerTube builds a PeerTube search engine, PodcastIndex builds a Podcast search engine ok good enough”. From my perspective the Owncast directory is there to show examples of Owncast streams, not as the solution for live stream discovery.
The good news is believe it or not we’re in the best possible scenario. We have a diverse collection of people, technologies and ideas at our fingertips. Big Tech only has what it has: a small-minded bubble that doesn’t have people in its best interests. We can do better because we can do anything when we build it ourselves.