Launching The Bat Player on the Roku Store and its aftermath
After a year of development The Bat Player went live on Roku's Channel Store.

The Bat Player first went public in September of last year. This means if you knew the right Roku Channel Code you could install it on your device. I put up a web site to make this easier, and shared it with a couple specific communities like the Roku forums and Reddit's Roku subreddit.
My goal all along was to get it available in their mainstream directory. But between their approval delays (It can take months for them to get you in their queue) and many requested change iterations, it took some time. Add a period early this year where I took time off trying to get it approved, and you'll see why it took so long.
But that's not what this post is about. It's about what happened after it went live.
But first let's quickly go over how The Bat Player works.
As far as the audio aspects go it's a pretty dumb application. It doesn't really know much. Due to Roku's limitations with streaming protocols it doesn't know even when a song changes. To overcome this I built a service, known as The Bat Server that can be ping'ed with a URL to find the title of what's playing on a station via a variety of different methods. This part I actually broke out in to my first public Node.js module.
Easy enough, but that's not what I wanted The Bat Server for. I wanted contextual, useful information. So knowing the artist name allows me to grab some relevant information from Last.FM's API. That too, is easy enough.
Song information is more difficult. I query a few different services (Last.FM, Discogs, Gracenote, Musicbrainz) to get an array of possible albums a track could be from. Then I try to make an educated guess based on available information. This whole song and dance is pretty expensive.
On top of this the client makes separate calls to The Bat Server to do some image manipulation for a few things (dynamic header images, station icon resizing, building backgrounds and artist images) via ImageMagick on the fly.
All this happens every time a new song is seen by The Bat Server. It's not efficient, it doesn't work at scale, and it was living on one tiny server. But I only had about 800 installs. So I figured eventually when I got approved for the Channel Store I'd get a couple hundred installs more one day, half of those people would try it, and things would level off and I could reassess down the road if needed. I underestimated the Roku Channel Store.
Once it was available thousands of new users brought The Bat Server to its knees the first day. My single t2.small EC2 instance was not up to the task, though in retrospect I did have a few things early on that I'm really thankful for now.
I cached everything. Data gets saved to Memcache, so an Artist, Album, Song only gets processed once. Also, images get pulled through Amazon Cloudfront. So those crazy dynamic images eventually make it to the edge servers and won't touch my server again. And lastly I put Varnish in front of the Node.js service as a way to have a handle on how long a previous request can stay as a cached result before we go to the internet radio station to determine what's playing again. If all fails I can dial up the cache duration.
I also added centralized logging and Analytics not just from the service, but also from the clients themselves. I did this with an Amplitude library I released and a syslog client I built into the client. Both written in Brightscript. I wanted insight on what was going out in the field.
But no amount of caching or logging was going to save this. Luckily I was already using EC2 for my existing instance, but now it was time to put myself through a self-run AWS Bootcamp.
First off, I needed to handle the new load. So I created a new t2.large and an Elastic Load Balancer. I pointed DNS for the existing server to the load balancer and put the two servers behind it. Things became much happier quickly, but I knew this was only a stop-gap measure. I needed some auto-scaling action.
Since I added the t2.large I bought myself some time to figure out what the best AWS CloudWatch metrics would be in my situation to scale capacity. At first my alarms were a bit too aggressive, causing servers to go in and out pretty frequently, but I eventually leveled them out, finally feeling confident enough to pull the t2.large out of the load balancer and let the system manage itself.
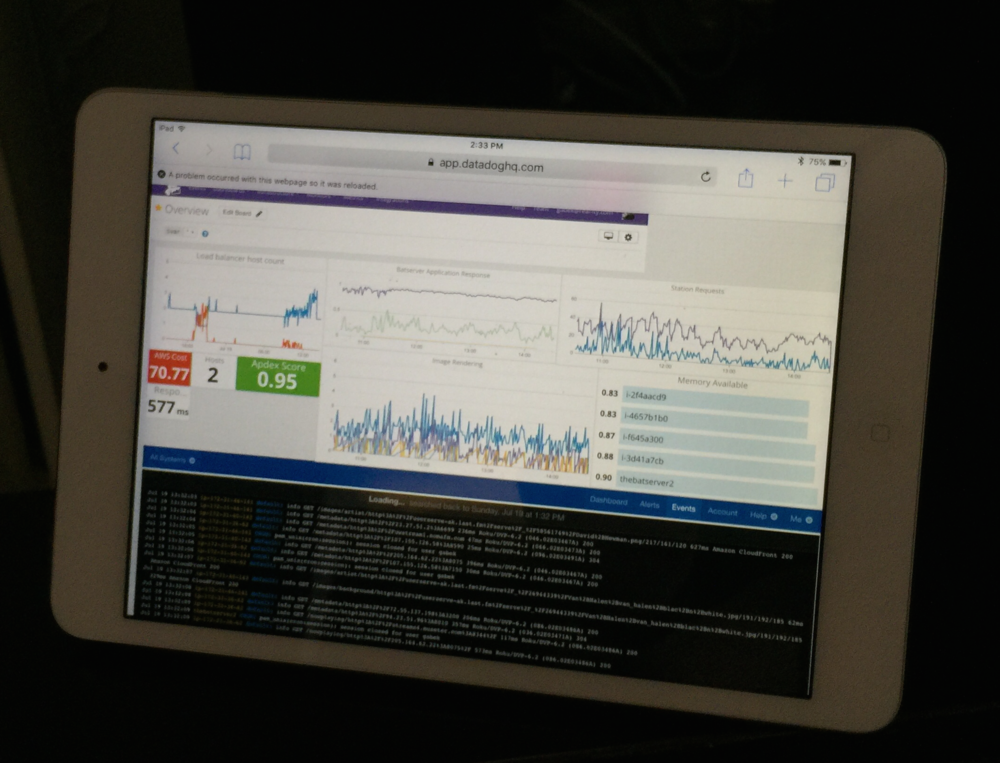
With this new infrastructure I needed some insight into it, so between Runscope for API monitoring (I so love this service), New Relic for server monitoring, Papertrail for the above logging, Rollbar for Node.js application error reporting, and Datadog I was able to put it all into one nice little interface. Add Zappier and Pushover with some webhooks and I now get custom alerts right to my Apple Watch. But man am I paying for a lot of services now. I hope once some time passes without any incident I can get rid of some of these services.
So now what? Well obviously things aren't perfect yet. Each server has its own instance of Varnish, so that's pretty stupid. But that's a side effect of my reactive-scaling. So maybe I'll [Varnish] -> ELB -> [Servers], but that would require an additional, full time EC2 instance just for caching, plus I read that putting an ELB behind Varnish isn't terribly awesome. I never thought I'd miss managing F5 BIG-IPs!
So what did I learn? The obvious, really. If you're going to build a single-homed, power hungry service, be prepared to scale horizontally. And what I did to fix it wasn't novel, it's what these AWS resources were created for. I also learned that the extra effort I put in up front both for analytics and logging made it easier to know what was going on. And lastly, utilizing the Right Tools For The Job**™,** in this case memcache, varnish, and the array of services from AWS, really allowed me to take something that would have only handled a few hundred users initially to something that I feel confident I can scale out to any size.
Enjoy the tunes!